Navierstokes
continuiti.benchmarks.navier_stokes
Navier-Stokes benchmark.
NavierStokes(dir=None)
¶
Bases: Benchmark
Navier-Stokes benchmark.
This benchmark contains a dataset of turbulent flow samples taken from neuraloperator/graph-pde that was used as illustrative example in the FNO paper:
Li, Zongyi, et al. "Fourier neural operator for parametric partial differential equations." arXiv preprint arXiv:2010.08895 (2020).
The dataset loads the NavierStokes_V1e-5_N1200_T20 file which contains
1200 samples of Navier-Stokes flow simulations at a spatial resolution of
64x64 and 20 time steps.
The benchmark exports operator datasets where both input and output function are defined on the space-time domain (periodic in space), i.e., \((x, y, t) \in [-1, 1] \times [-1, 1] \times (-1, 0]\) for the input function and \((x, y, t) \in [-1, 1] \times [-1, 1] \times (0, 1]\) for the output function.
The input function is given by the vorticity field at the first ten time steps \((-0.9, -0.8, ..., 0.0)\) and the output function by the vorticity field at the following ten time steps \((0.1, 0.2, ..., 1.0)\).
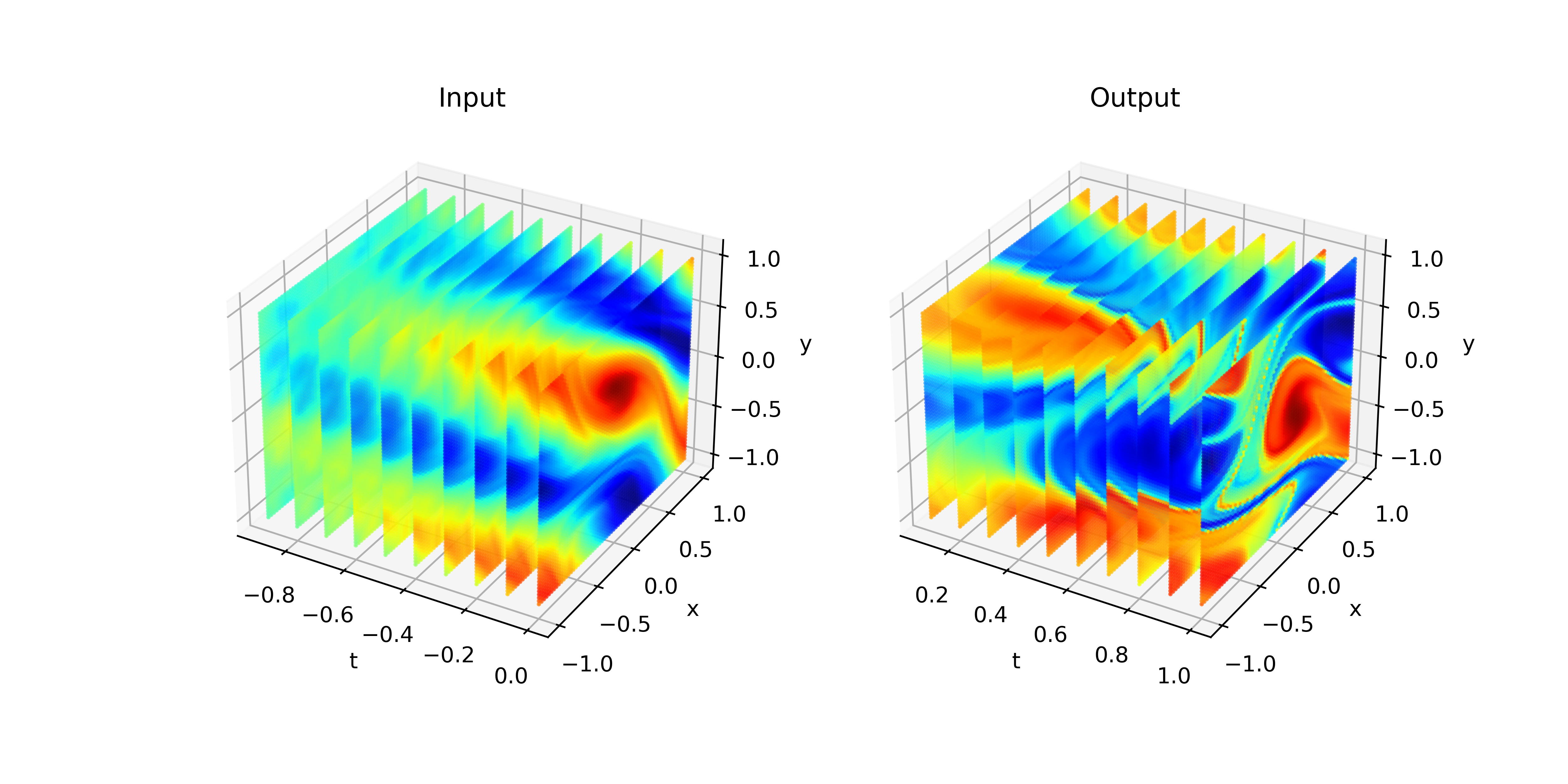
The datasets have the following shapes:
len(benchmark.train_dataset) == 1000
len(benchmark.test_dataset) == 200
x.shape == (3, 64, 64, 10)
u.shape == (1, 64, 64, 10)
y.shape == (3, 64. 64, 10)
v.shape == (1, 64, 64, 10)
| PARAMETER | DESCRIPTION |
|---|---|
dir |
Path to data set. Default is |
Source code in src/continuiti/benchmarks/navierstokes.py
Created: 2024-08-20