Dynamic Programming#
Dynamic programming (DP) is a method that in general solves optimization problems that involve making a sequence of decisions (multi-stage decision making problems) by determining, for each decision, subproblems that can be solved similarily, such that an optimal solution of the original problem can be found from optimal solutions of subproblems. This method is based on Bellman’s Principle of Optimality:
An optimal policy has the property that whatever the initial state and initial decision are, the remaining decisions must constitute an optimal policy with regard to the state resulting from the first decision.
A problem is said to satisfy the Principle of Optimality if the sub-solutions of an optimal solution of the problem are themselves optimal solutions for their subproblems.
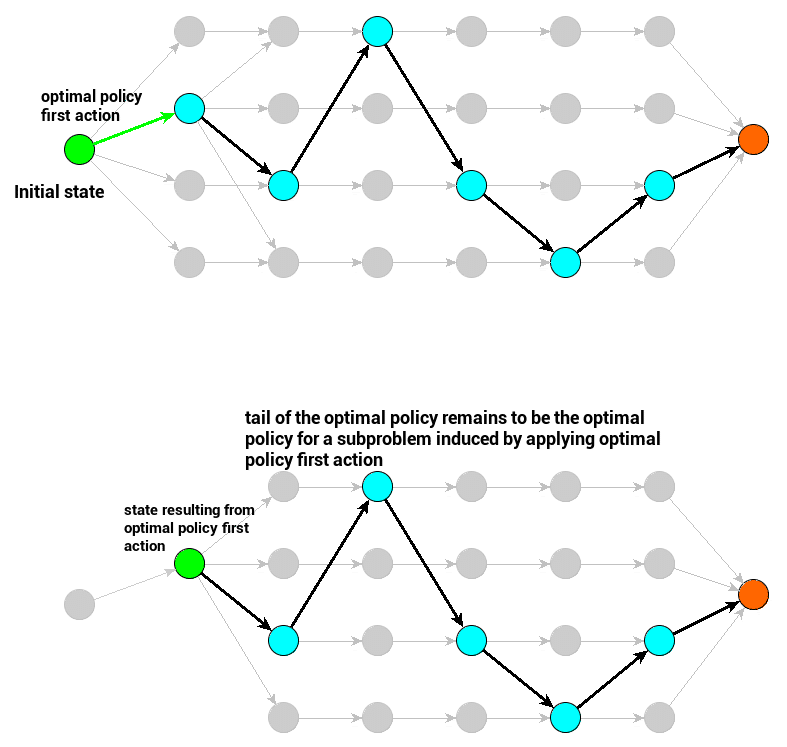
Fig. 8 Representation of optimality principle on a graph. Taken from this blog post.#
Black arrows represent sequence of optimal policy actions – the one that is evaluated with the greatest value.
Green arrow is optimal policy first action (decision) – when applied it yields a subproblem with new initial state. Principle of optimality is related to this subproblem optimal policy.
Green circle represents initial state for a subproblem (the original one or the one induced by applying first action)
Red circle represents terminal state – assuming our original parametrization it is the maze exit
Usually creativity is required before we can recognize that a particular problem can be cast effectively as a dynamic program and often subtle insights are necessary to restructure the formulation so that it can be solved effectively.
Dynamic Programming is a very general solution method for problems which have these properties:
Optimal substructure (Principle of optimality applies)
The optimal solution can be decomposed into subproblems, e.g., shortest path.
Overlapping subproblems
The subproblems recur many times.
The solutions can be cached and reused.
Additive cost function
The cost function along a given path can be decomposed as the sum of cost functions for each step.
It is used across a wide variety of domains, e.g.
Scheduling algorithms
Graph algorithms (e.g., shortest path algorithms)
Graphical models in ML (e.g., Viterbi algorithm)
Bioinformatics (e.g., Sequence alignment, Protein folding)
Finance (e.g. Derivatives)
Discrete Time#
We define the optimal cost-to-go function (also known as value function) for any feasible \(\mathbf{x} \in \mathbf{X}\) as[1]:
An admissible control sequence \(\mathbf{u}^*\) is called optimal, if
Infinite Horizon#
Given the optimal cost-to-go for an infinite-horizon optimal control problem:
We can unroll the expression by one-step to obtain:
Which is equivalent to:
If we now replace \(\mathbf{x}_1 = f(\mathbf{x}_0, \mathbf{u}_0)\) and then get rid of time indices we finally get:
This equation is called the Bellman equation.
DP Algorithm#
For every initial state \(\mathbf{x}_0\), the optimal cost is equal to \(V(\mathbf{x}_0)\), given by the last step of the following algorithm, which proceeds backward in time from stage \(N-1\) to stage \(0\):
Start with \(V(\mathbf{x}_N) = c(\mathbf{x}_N)\)
then for \(k = \{N - 1, \dots, 0\}\), let:
\[ V(\mathbf{x}_k) = \displaystyle \min_{u \in \mathbf{U}} \left[ c(\mathbf{x}_k, \mathbf{u}_k) + V(f(\mathbf{x}_k, \mathbf{u}_k)) \right] \]\[ V(\mathbf{x}_k) = \displaystyle \min_{u \in \mathbf{U}} \left[ c(\mathbf{x}_k, \mathbf{u}_k) + V(\mathbf{x}_{k+1}) \right] \]
Once the values \(V(\mathbf{x}_0), \dots , V(\mathbf{x}_N)\) have been obtained, we can use a forward algorithm to construct an optimal control sequence \(\{u_0^*, \dots, u_{N-1}^*\}\) and corresponding state trajectory \(\{x_1^∗, \dots, x_{N}^*\}\) for the given initial state \(x_0\).
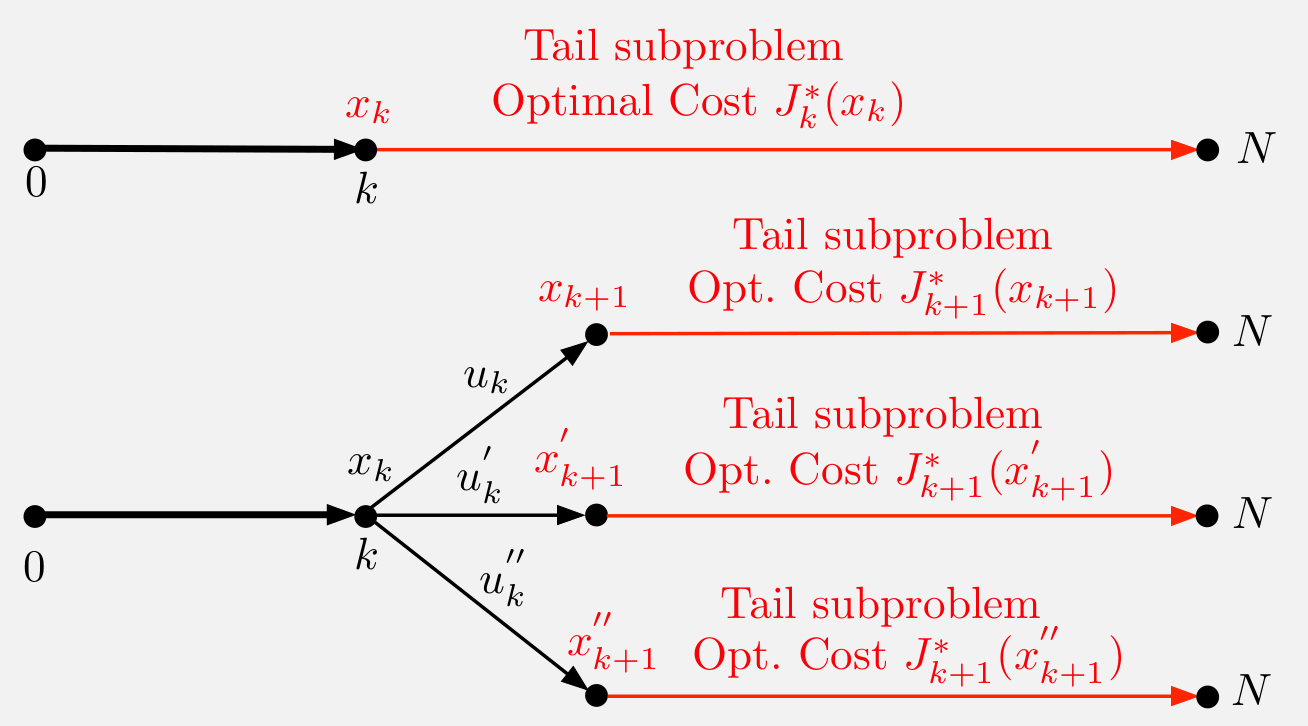
Fig. 9 Illustration of the DP algorithm. The tail subproblem that starts at \(x_k\) at time \(k\) minimizes over \(\{u_k , \dots , u_{N-1}\}\) the “cost-to-go” from \(k\) to \(N\).#
Graph Search#
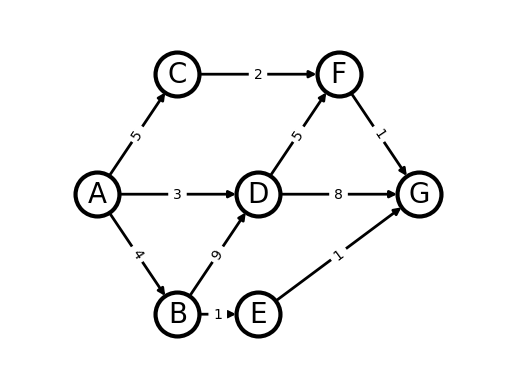
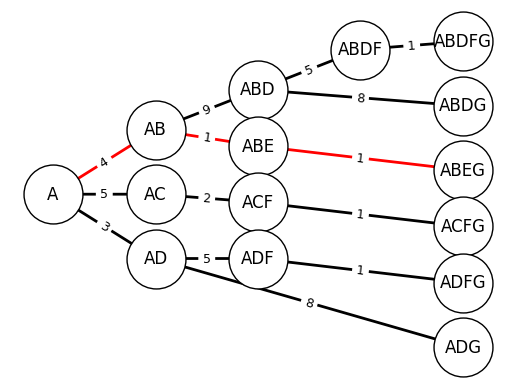
We wish to travel from node A to node G at minimum cost. If the cost represents time then we want to find the shortest path from A to G.
Arrows (edges) indicate the possible movements.
Numbers on edges indicate the cost of moving along an edge.
We can use Dynamic Programming to solve this problem.
We start by determining all possible paths first .
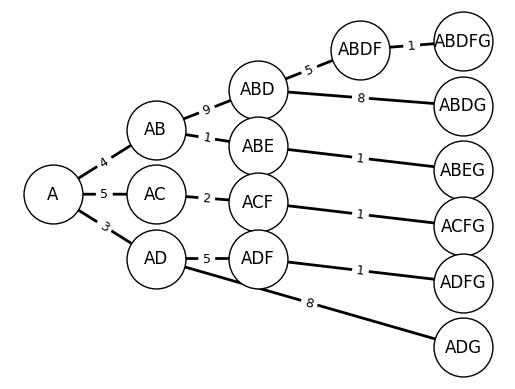
We then compute the cost-to-go at each node to determine the shortest path.
Each node in this new graph represents a state. We will start from the tail (the last states) and compute recursively the cost for each state transition.
Let \(c(n_1, n_2)\) the cost of moving from node \(n_1\) to node \(n_2\) and \(V(n)\) be the optimal cost-to-go from node \(n\).
We have \(V({\text{G}}) = 0\) because the cost of going from node \(G\) to itself is 0.
We start with nodes F and E:
We then move to nodes D and C:
After that we move to node B:
We finally go to node A:
Now that we have computed the optimal cost-to-go, we can proceed in a forward manner to determine the best path:
For the first action (step) we have:
Proceeding the same way we get:
The shortest-path is ABEG.
Value Iteration#
Another way to compute the optimal cost-to-go for all states that is also applicable is the Value Iteration algorithm:
Tip
Stochastic Value Iteration
It can also be used in stochastic systems:
Optimal Control as Graph Search#
We can formulate discrete-time optimal control problems as graph search problems by either considering a system with discrete states and actions or by discretizing a system with continuous states and actions.
Exercise#
Exercise 2 (Grid World)
Show code cell source
env = create_grid_world_environment(render_mode="rgb_array", max_steps=50)
result = simulate_environment(env)
show_video(result.frames, fps=3)
 |
The task can be represented as the following undirected graph:
Show code cell source
env.reset()
G = env.unwrapped.get_graph()
plot_grid_graph(G)
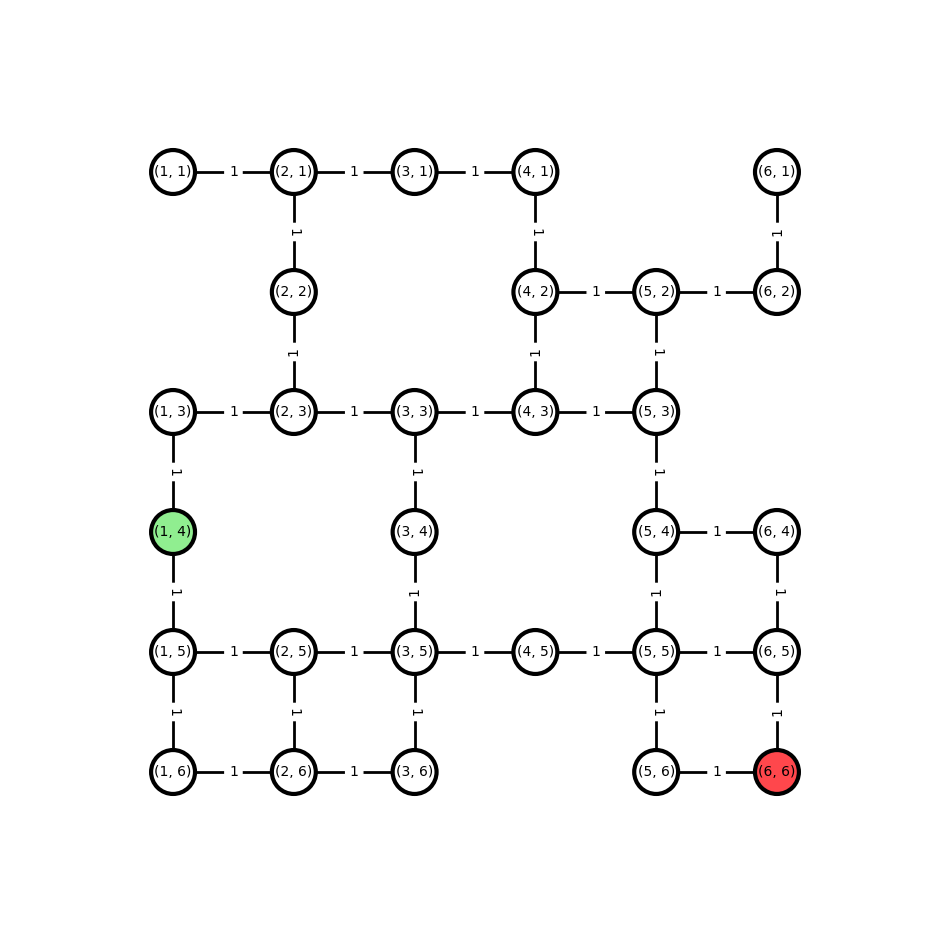
We convert the graph to a directed graph with all possible paths from start to target that do not contain cycles
Show code cell source
G = convert_graph_to_directed(G)
plot_grid_graph(G)
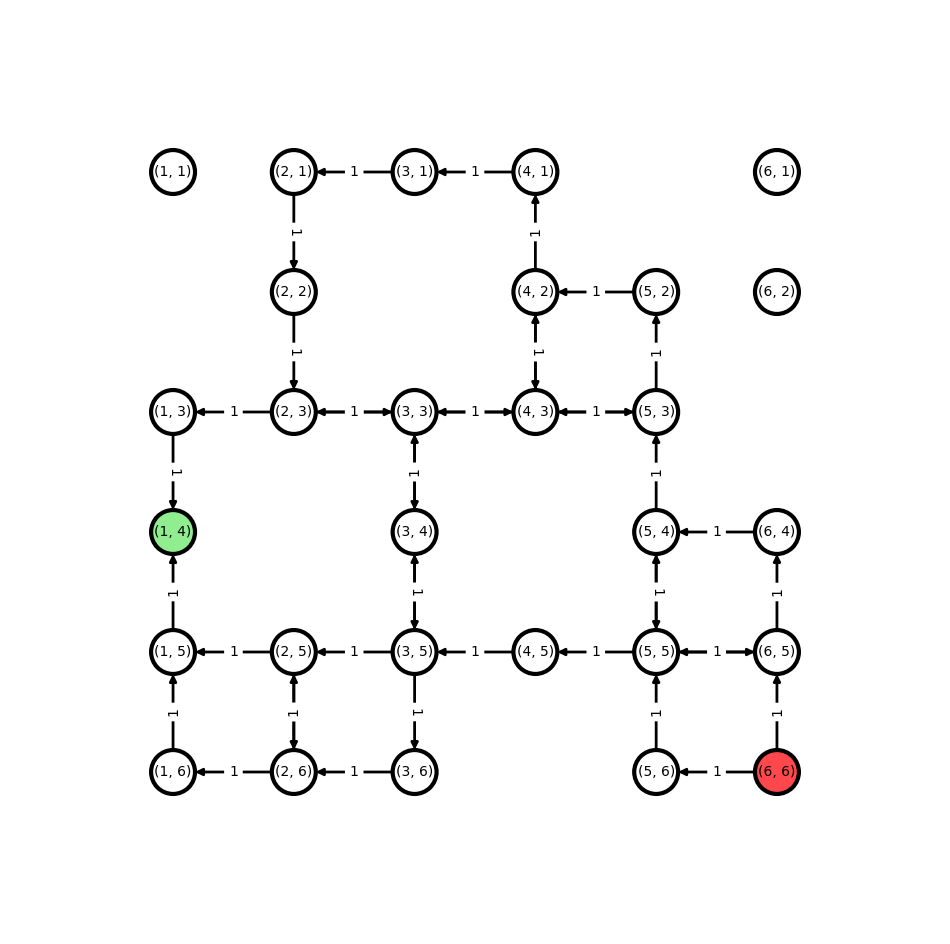
We wish for the car to travel from its starting cell in red to the target cell in green. If the cost represents time and each step has the same cost then we want to find the shortest path to the goal.
Arrows (edges) indicate the possible movements.
Numbers on edges indicate the cost of moving along an edge.
Use Dynamic Programming to solve this problem:
Determine the number of possible paths from start position to target position.
Compute the optimal cost-to-go for each state.
Determine the optimal plan using the computed optimal cost-to-go.
Implement the plan in the environment.
Tip
Hint 1
Determine all possible paths first.
You can use plot_grid_all_paths_graph(G) for that.
Tip
Hint 2
Compute the optimal cost-to-go at each node.
You can use dict(G.nodes(data=True)) to get a dictionary that maps the nodes to their attributes
and you can use G.start_node and G.target_node to access the start and target nodes, respectively.
Solution to ( 2
For this solution we first need to import some functions:
from training_ml_control.environments import (
value_iteration,
compute_best_path_and_actions_from_values,
)
import networkx as nx
To determine the number of paths from start node to target node we use:
len(
list(
nx.all_simple_paths(
G.to_undirected(), source=G.start_node, target=G.target_node, cutoff=len(G)
)
)
)
101
After that, to plot all paths from start to end we use:
plot_grid_all_paths_graph(G)

To compute the optimal cost-to-go we use:
values = value_iteration(G)
Once that’s computed, we can determine the best path and correponding actions:
best_path, actions = compute_best_path_and_actions_from_values(
G, start_node=G.start_node, target_node=G.target_node, values=values
)
print(f"{best_path=}")
print(f"{actions=}")
best_path=[(6, 6), (6, 6), (5, 6), (5, 5), (4, 5), (3, 5), (2, 5), (1, 5)]
actions=[2, 3, 2, 2, 2, 2, 3]
We finally apply the computed plan to the environment and check that it indeed works:
env.reset()
for action in actions:
observation, _, terminated, truncated, _ = env.step(action)
if terminated or truncated:
frames = env.render()
env.reset()
break
env.close()
show_video(frames, fps=3)
 |
Continuous Time#
Let’s consider a continuous-time optimal control problem with finite horizon over the time period \([t_0 ,t_f]\).
The system’s dynamics is given by:
With the initial state \(\mathbf{x}(t_0) = \mathbf{x}_0\)
The cost-to-go is given by:
The optimal cost-to-go is given by:
It can be show that for every \(s, \tau \in [t_0, t_f]\), \(s \leq \tau\) , and \(\mathbf{x} \in \mathbf{X}\), we have:
Which is another version of the Bellman equation.
Hamilton-Jacobi-Bellman Equation#
The Hamilton-Jacobi-Bellman (HJB) equation is given by:
It is a sufficient condition of optimality i.e., that if \(V\) satisfies the HJB, it must be the value function.