MPC and AlphaZero#
AlphaZero is a computer program developed by artificial intelligence research company DeepMind to master the games of chess, shogi and go.
It is built from three core pieces:
Value Function (Neural Network) to estimate the optimal cost-to-go for any given state.
Policy (Neural Network) to determine the action to take at a given state.
Monte Carlo Tree Search (MCTS) to simulate and search for the best plan.
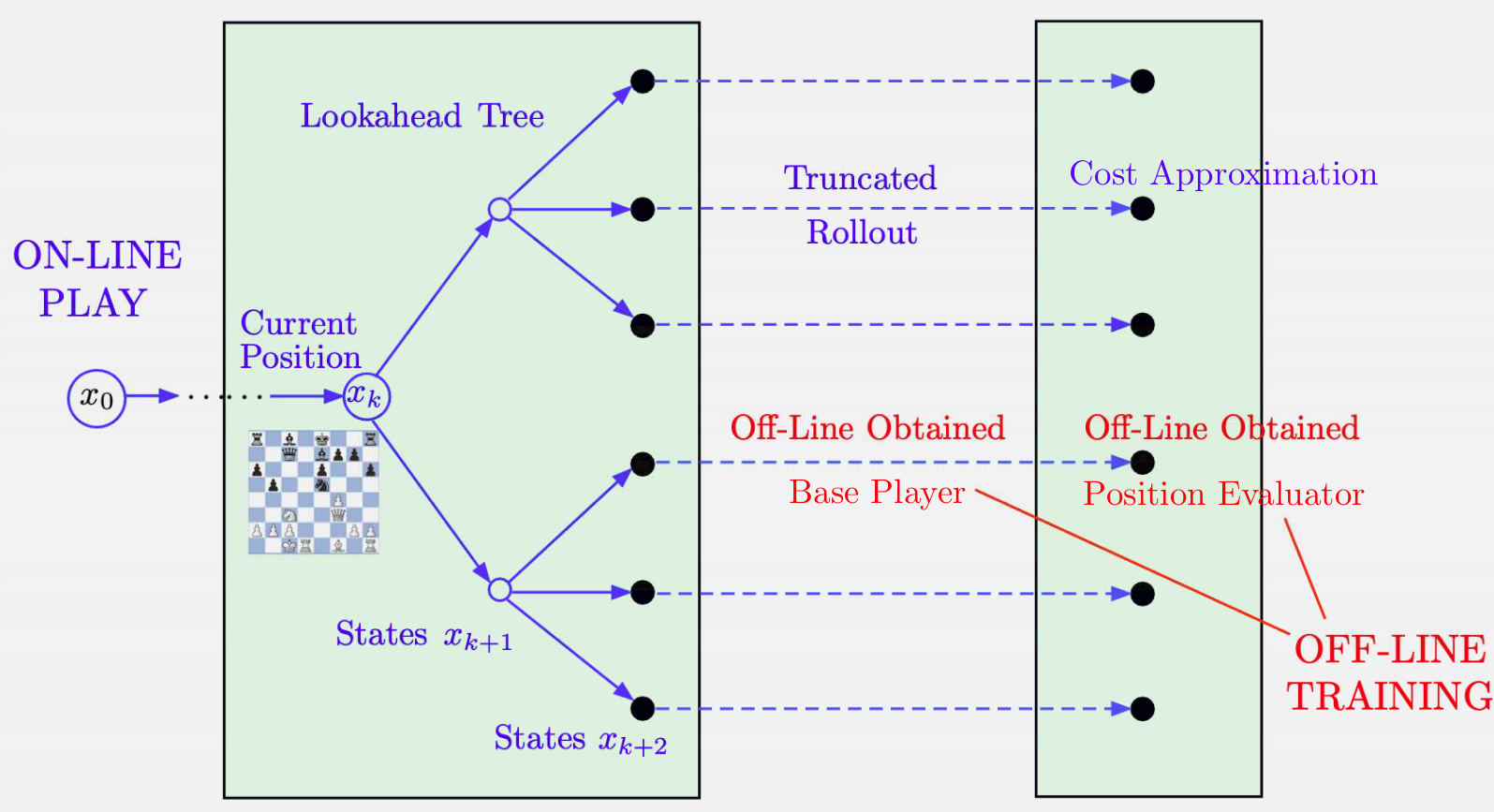
Fig. 16 Illustration of an on-line player such as the one used in AlphaGo, AlphaZero, and Tesauro’s backgammon program. At a given position, it generates a lookahead tree of multiple moves up to some depth, then runs the off-line obtained player for some more moves, and evaluates the effect of the remaining moves by using the position evaluator of the off-line player.#
In AlphaZero, the policy and value networks are trained off-line and an approximate version of the fundamental DP algorithm of policy iteration. A separate on-line player is used to select moves, based on multistep lookahead minimization and a terminal position evaluator that was trained using experience with the off-line player.
This approach performs better than using the off-line policy directly because of the long lookahead minimization, which corrects for the inevitable imperfections of the neural network-trained off-line player, and position evaluator/terminal cost approximation.
In model predictive control (MPC), there is no off-line training and we use the system’s model for the on-line rollout. The control interval is equivalent to the number of steps in lookahead minimization, while the prediction interval is equivalent to the total number of steps in lookahead minimization and truncated rollout.
Monte Carlo Tree Search#
Monte Carlo Tree Search (MCTS) is a heuristic search algorithm which uses stochastic simulations for decision processes, most notably those employed in software that plays board games. In that context MCTS is used to solve the game tree.
MCTS was combined with neural networks in 2016 and has been used in multiple board games like Chess, Shogi, Checkers, Backgammon, Contract Bridge, Go, Scrabble, and Clobber as well as in turn-based-strategy video games (such as Total War: Rome II’s implementation in the high level campaign AI).
The method especially took off due its effectiveness in computer Go and is still being used in DeepMind’s AlphaGoZero the most advanced Go AI to date.
MCTS consists of 4 steps that are repeated until some condition is met:
Selection: The selection phase traverses the tree level by level, each time selecting a node based on stored statistics like “number of visits” or “total reward”. The rule by which the algorithm selects is called the tree policy. Selection stops when a node is reached that is not fully explored yet, i.e. not all possible moves have been expanded to new nodes yet.
Expansion: The expansion step consists of adding one or multiple new child nodes to the final selected node.
Rollout: A rollout is initiated from each of these added nodes. Depending on the mean depth of the tree, rollout is done until the end of the game or as deep as possible before performing an evaluation. When dealing with terminal states in games the evaluation is done based on the win condition and usually yields 0 (loss), 0.5 (draw) or 1 (win). In the original algorithm the rollout is performed at random, but in general the so-called default policy can be enhanced by heuristics. For example, in the case of AlphaGoZero the rollout step was completely replaced by a neural network evaluation function.
Backup: The outcome of the rollout step is backed up to the nodes involved in the selection phase by updating their respective statistics
