Machine Learning & Control#
Modern machine learning provides useful tools and perspectives for control theory. Framing control problems as data modeling tasks enables powerful function approximation, estimation, and optimization techniques from machine learning to be applied.
Learning-Based Control#
Learning-based control addresses the automated and data-driven generation or adaptation of elements of the controller formulation to improve control performance.
The learning setup can be diverse:
Offline learning involves adapting the controller between trials or episodes while collecting data.
Online learning adjusts the controller during closed-loop operation (e.g. repetitive tasks) or using data from one task execution.
System Identification#
System Identification is the process of constructing a model of a (dynamical) system from observations (measurements) of its inputs and outputs. System identification also includes the optimal design of experiments for efficiently generating informative data for fitting such models as well as model reduction.
In control engineering, the objective is to obtain a good performance of the closed-loop system, which is the one comprising the physical system, the feedback loop and the controller. This performance is typically achieved by designing the control law relying on a model of the system, which needs to be identified starting from experimental data. If the model identification procedure is aimed at control purposes, what really matters is not to obtain the best possible model that fits the data, as in the classical system identification approach, but to obtain a model satisfying enough for the closed-loop performance.
In control engineering, we typically rely on the mathematical modelling of the system from first principles and then optionally use parameter identification methods to determine the values of the mathematical model’s parameters.
In our case, we will not rely on that and instead prefer fitting a model based only on measured data.
Exercise 6 (Dynamic System Model Evaluation)
How do we evaluation the fitted model of the system?
Solution to ( 6
We could evaluate the model’s prediction on a held-out validation set.
Additionally we could evaluate the model’s long-term predictions in an open-loop manner.
On top of that, we could evaluate the model’s step[1] and impulse[2] responses from different initial states. This is especially useful for linear systems.
It is also valuable to look at what the model’s residuals and make sure there is no correlation with other available information such as the input.
Data Collection#
Before learning a model of the system, we need to collect either during the system’s operation i.e. online data collection, or inbetween episodes of the system’s operation i.e. offline data collection. The collected data has to be informative, i.e. comprehensive and be representative of the all behaviours of the system that we desire to capture.
Data informativity is a condition on the data under which it is possible to distinguish between different models in a (parametric) model class.
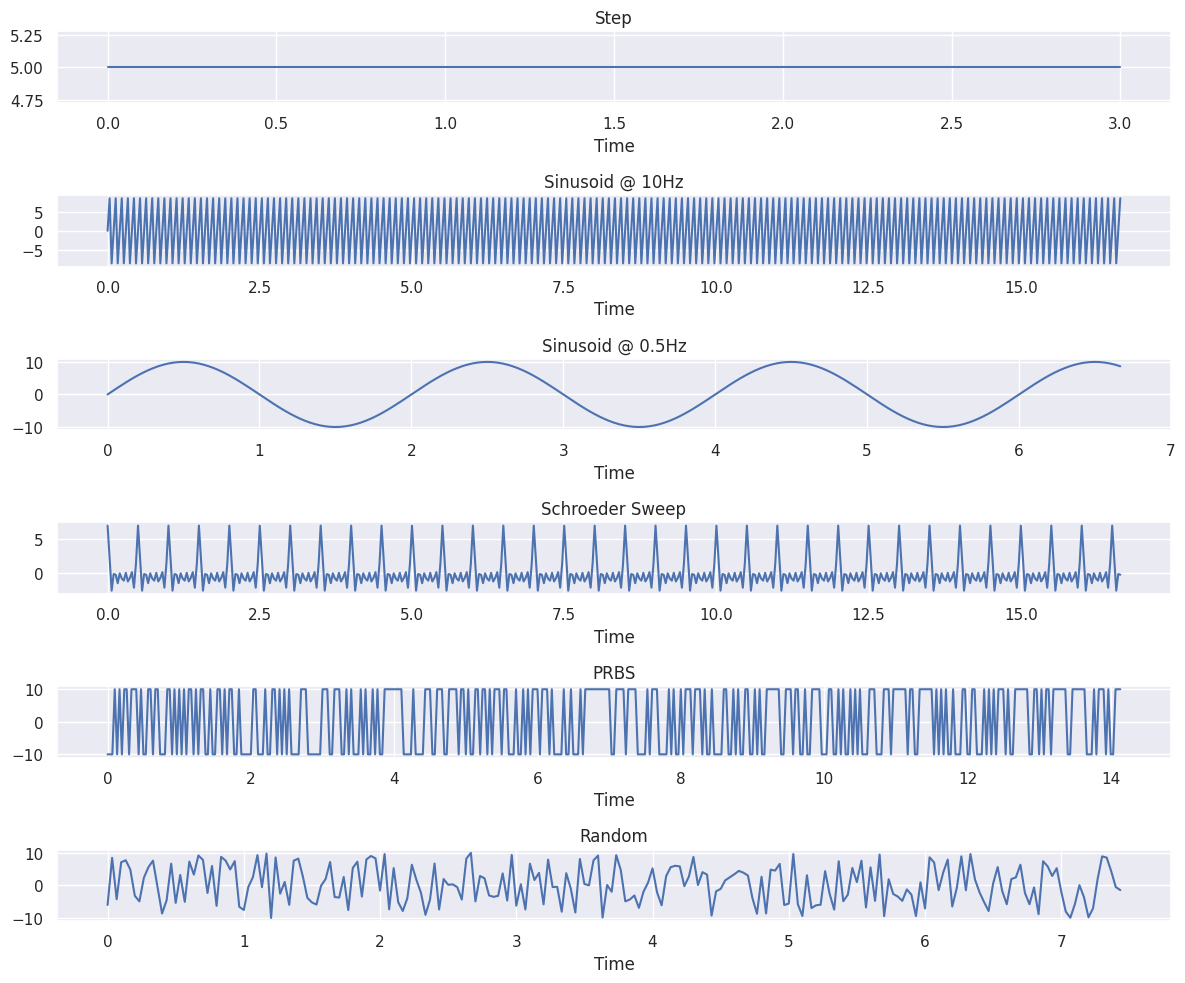
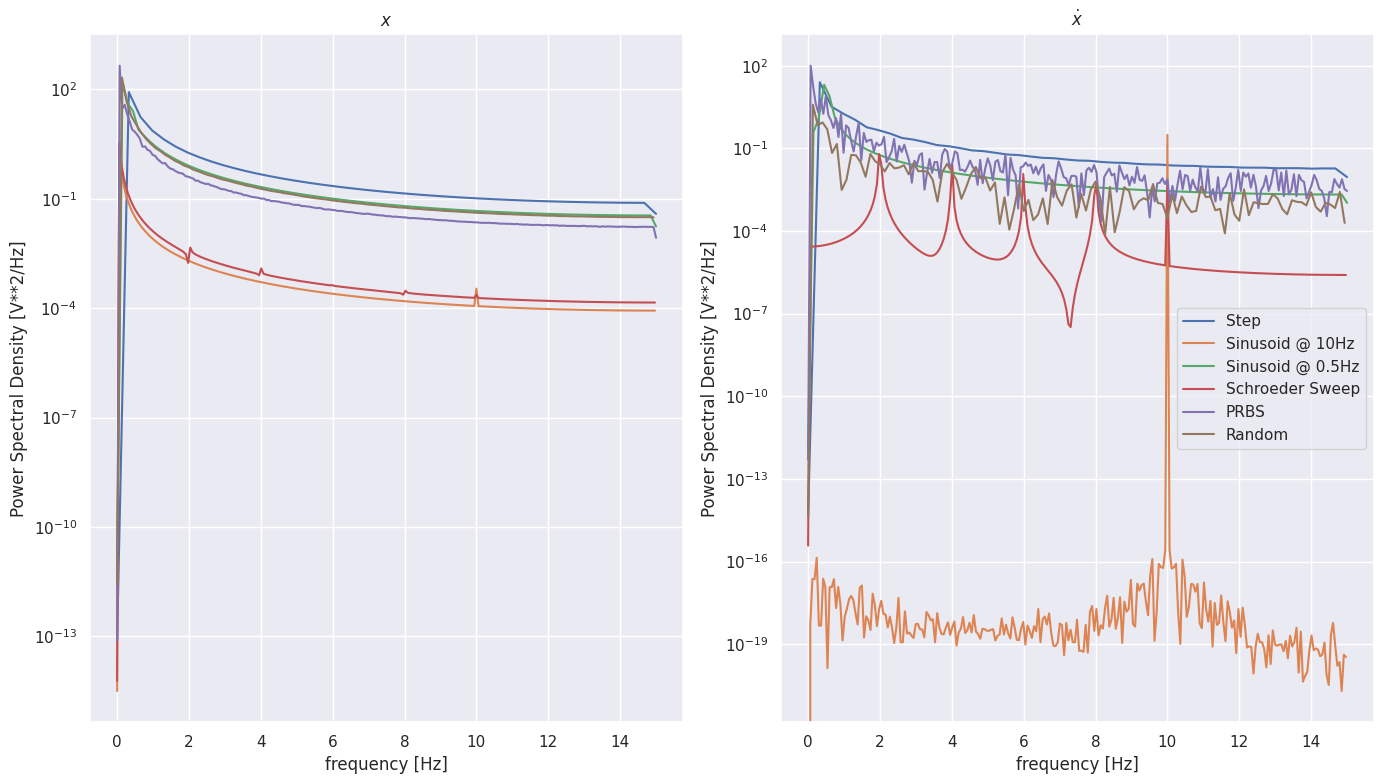
Commonly used input signals for system identification:
Step function
Pseudorandom binary sequence (PRBS)
Autoregressive, moving average process
Periodic signals: sum of sinusoids
Schroeder Sweep (Sum of phase shifted sinusoids)
\[ u(t) = \sum\limits_{k=1}^M A_k \cos(\frac{2\pi k \tau(t)}{T} + \phi_k), \quad t = 0, 1, \dots , N − 1 \]Where:
\[\begin{split} \begin{array}{l} k = \sqrt{\frac{P}{M}}\\ \phi_1 = 0\\ \phi_k = \phi_{k-1} − \frac{\pi k^2}{N}, \quad k = 2, 3, \dots , M \end{array} \end{split}\]With \(M\) the number of harmonically related frequencies, \(\phi_k\) the phase angles of the harmonic components to produce low Peak Factor (PF), \(N\) the number of time steps, \(P\) the total desired input power.
For certain systems in many safety-critical tasks such as space exploration or robot-assisted surgery we have to rely on human experts to control the system and avoid damaging it or its environment.
Cart#
cart_env = create_cart_environment(max_steps=500, goal_position=20, max_position=30)
Show code cell content
cart_observations = {}
cart_actions = {}
cart_frames = {}
controllers = {
"Step": ConstantController(np.asarray([cart_env.max_action / 2])),
"Sinusoid @ 10Hz": SineController(
cart_env, np.asarray([cart_env.max_action]), frequency=10
),
"Sinusoid @ 0.5Hz": SineController(
cart_env, np.asarray([cart_env.max_action]), frequency=0.5
),
"Schroeder Sweep": SchroederSweepController(
cart_env,
n_time_steps=500,
n_harmonics=5,
frequency=2,
),
"PRBS": PRBSController(np.asarray([cart_env.max_action])),
"Random": RandomController(cart_env),
}
for controller_name, controller in controllers.items():
result = simulate_environment(cart_env, controller=controller)
cart_observations[controller_name] = result.observations
cart_actions[controller_name] = result.actions
cart_frames[controller_name] = result.frames
error: XDG_RUNTIME_DIR not set in the environment.
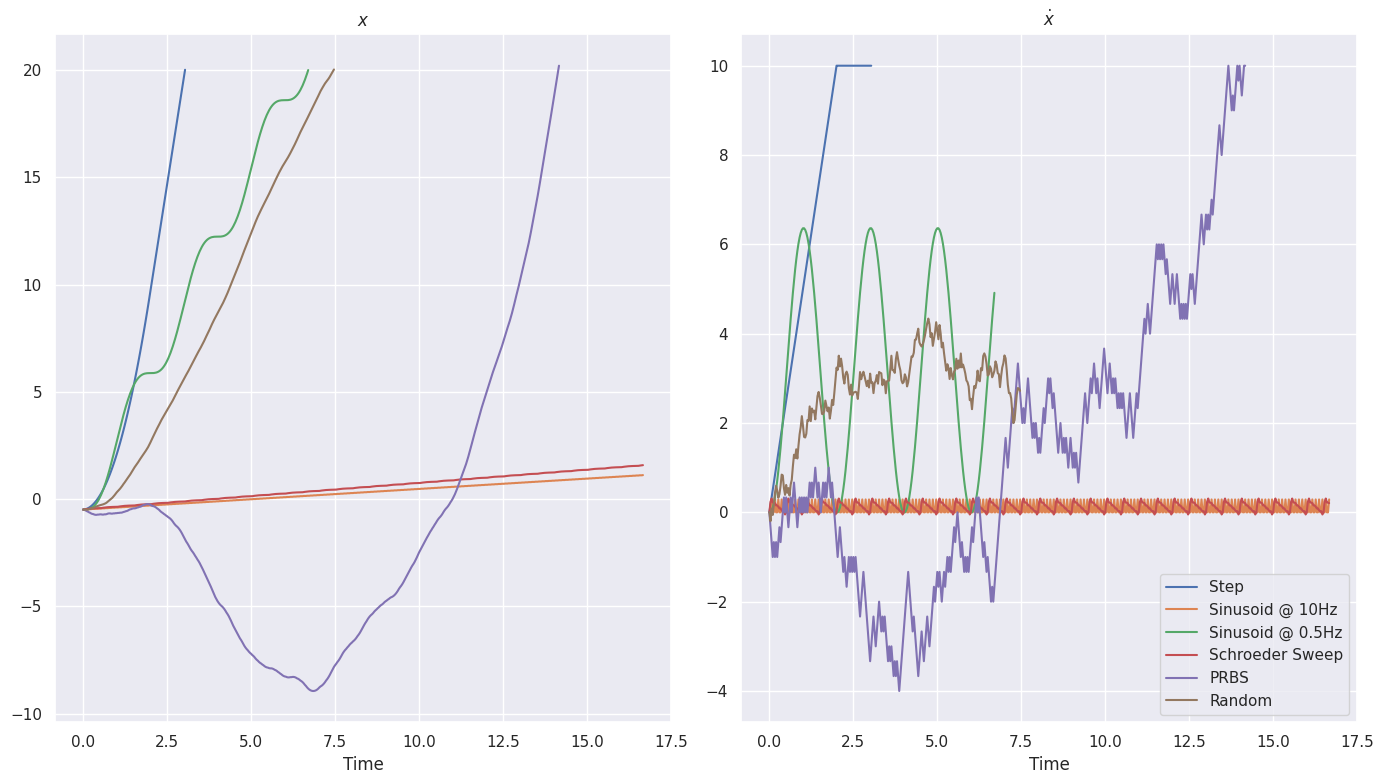
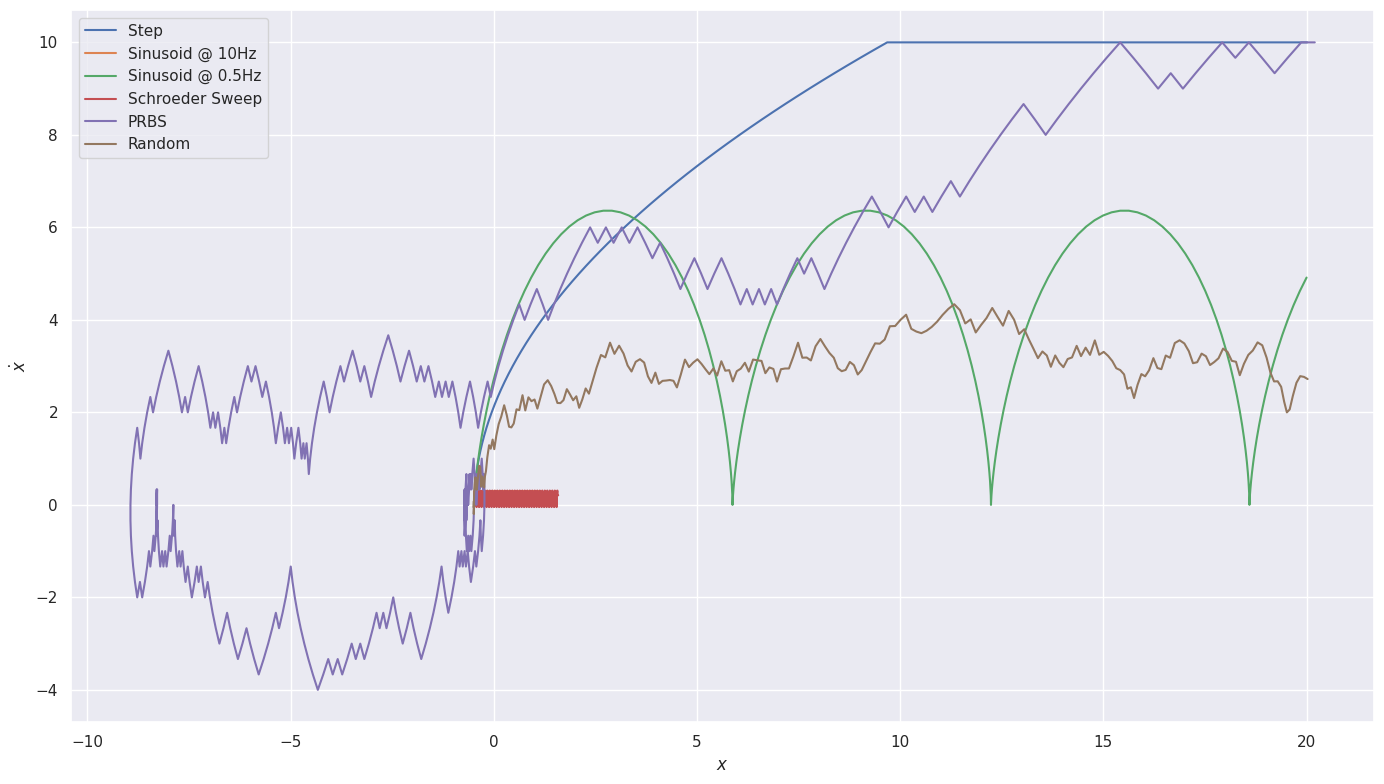
Let’s look at the phase portrait[3] instead.
Let’s visualize the Power Spectral Density (PSD) of the input and state signals
Model Fitting#
Naive Deep Learning#
Where \(\theta\) are learnable parameters.
Issues with such an approach:
Domain shift from the training distribution to the real-world distribution.
Black-box.
Deep Learning with Nominal Model#
A real-world dynamical system can be described as:
Where \(f_n\) is the nominalsystem model, \(g_r\) an additive residual term accommodating uncertainty and \(w_t\) represents distburnances.
Many learning-based techniques make use of this explicit distinction by only learning the residual term.
An example of the use of this approach can be found in [SSOConnell+19].
Visual depiction of the ground effect, the complex aerodynamic effect between the drone and the ground, which is nonlinear, nonstationary, and very hard to model using standard system identification approaches. Adapted from Neural Control blog post. is a figure depicting the ground effect that is modelled using a neural network and Comparison of drone landing with and without neural network modelling of residual ground effect. Taken from Neural Control blog post. is a comparison of drone landings with and without neural network modeling.
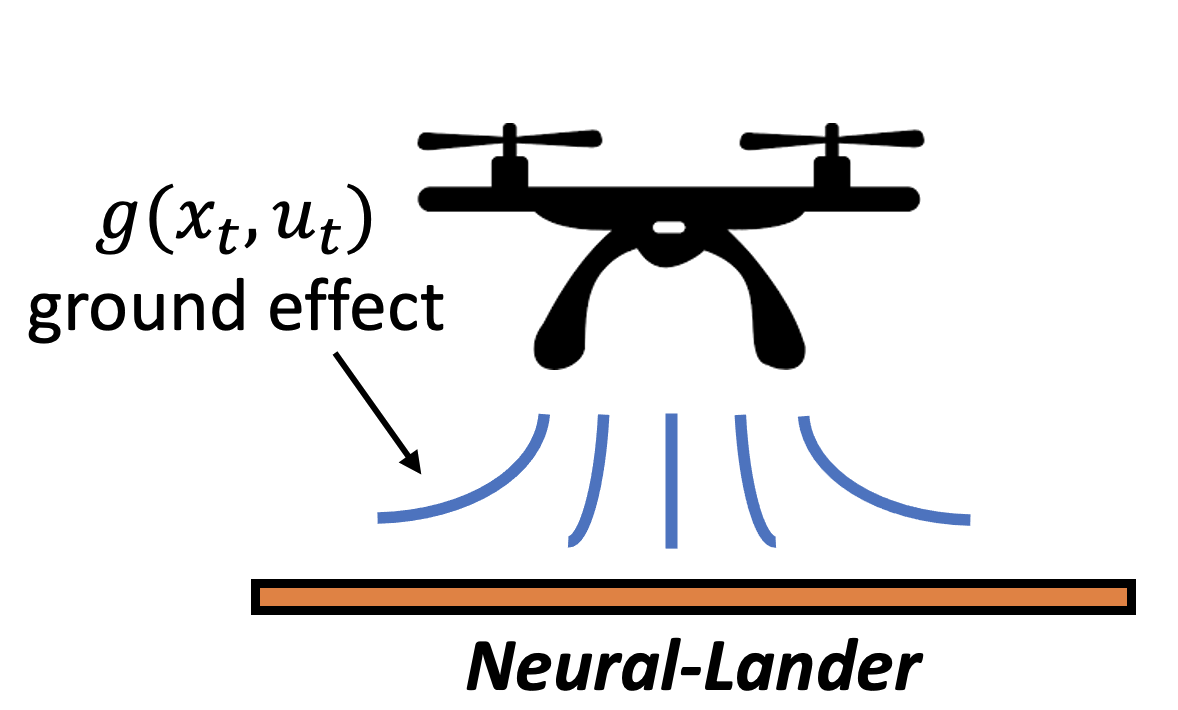
Fig. 17 Visual depiction of the ground effect, the complex aerodynamic effect between the drone and the ground, which is nonlinear, nonstationary, and very hard to model using standard system identification approaches. Adapted from Neural Control blog post.#

Fig. 18 Comparison of drone landing with and without neural network modelling of residual ground effect. Taken from Neural Control blog post.#
Issues with such an approach:
Requires nominal model.
Still susceptible to domain shift issues.
Sparse Identification of Nonlinear Dynamics (SINDy)#
The SINDY algorithm identifies fully nonlinear dynamical systems from measurement data. This relies on the fact that many dynamical systems have relatively few terms in the right hand side of the governing equations:
To determine the function \(f\) from data, we collect a time history of the state \(\mathbf{x}\) and either measure the derivative \(\dot{\mathbf{x}}\) or approximate it numerically. The data are sampled at several times \(t_1, t_2, \dots, t_m\) and arranged into two matrices:
Next, we construct a library \(\Theta(\mathbf{X})\) consisting of candidate non-linear functions of the columns of \(\mathbf{X}\). For example, \Theta(\mathbf{X})$ may consist of constant, polynomial, and trigonometric terms:
Here, higher polynomials are denoted as \(\mathbf{X}^{P_2}\), \(\mathbf{X}^{P_3}\), etc., where \(\mathbf{X}^{P_2}\) denotes the quadratic nonlinearities in the state x:
Each column of \(\Theta(\mathbf{X})\) represents a candidate function for the right-hand side of the system’s ODE. There is tremendous freedom in choosing the entries in this matrix of nonlinearities.
Because we assume that only a few of these nonlinearities are active in each row of \(f\), we may set up a sparse regression problem to determine the sparse vectors of coefficients \(\Xi = \begin{bmatrix} \xi_1 ^ \xi_2 & \dots & \xi_n \end{bmatrix}\) that determine which nonlinearities are active:
This is illustrated in Schematic of the SINDy algorithm, demonstrated on the Lorenz equations. Data are collected from the system, including a time history of the states \mathbf{X} and derivatives \dot{\mathbf{X}}. Next, a library of nonlinear functions of the states, \Theta(\mathbf{X}), is constructed. This is then used to find the fewest terms needed to satisfy \dot{\mathbf{X}} = \Theta(\mathbf{X})\Xi. The few entries in the vectors of \Xi, solved for by sparse regression, denote the relevant terms in the right-hand side of the dynamics. Taken from brunton_discovering_2016. Each column \(\xi_k\) of \(Xi\) is a sparse vector of coefficients determining which terms are active in the right-hand side for one of the row equations:

Fig. 19 Schematic of the SINDy algorithm, demonstrated on the Lorenz equations. Data are collected from the system, including a time history of the states \(\mathbf{X}\) and derivatives \(\dot{\mathbf{X}}\). Next, a library of nonlinear functions of the states, \(\Theta(\mathbf{X})\), is constructed. This is then used to find the fewest terms needed to satisfy \(\dot{\mathbf{X}} = \Theta(\mathbf{X})\Xi\). The few entries in the vectors of \(\Xi\), solved for by sparse regression, denote the relevant terms in the right-hand side of the dynamics. Taken from [BPK16a]#
SINDy with Control (SINDyc)#
SINDYc generalizes the SINDY method to include inputs and control. In particular, it considers the nonlinear dynamical system with inputs \(\mathbf{u}\):
The SINDY algorithm is readily generalized to include actuation, as this merely requires building a larger library \(\Theta(\mathbf{X}, \mathbf{U})\) of candidate functions that include \(u\); these functions can include nonlinear cross terms in \(\mathbf{x}\) and \(\mathbf{u}\). This extension requires measurements of the state \(\mathbf{x}\) as well as the input signal \(\mathbf{u}\).

Fig. 20 Schematic of the SINDy with control algorithm. Active terms in a library of candidate nonlinearities are selected via sparse regression. Taken from [FKK+21].#
Koopman Operator#

Fig. 21 Summary of the idea of Koopman operators. By lifting to a space of observables, we trade a nonlinear finite-dimensional system for a linear infinite-dimensional system. Taken from [Col23].#
Given \(\mathcal{F}\) a space of functions \(g: \Omega \rightarrow \mathbb{C}\), and \(\Omega\) the state space of our dynamical system. The Koopman operator is defined on a suitable domain \(\mathcal{D}(\mathcal{K}) \subset \mathcal{F}\) via the composition formula:
Where \(\mathbf{x}_{t+1} = f(\mathbf{x}_t)\)
The functions \(g\), referred to as observables, serve as tools for indirectly measuring the state of the system. Specifically, \(g(x_t)\) indirectly measures the state \(x_t\).
In this context, \([\mathcal{K}g](\mathbf{x}_t) = g(f(\mathbf{x}_t)) = g(\mathbf{x}_{t+1})\) represents the measurement of the state one time step ahead of \(g(\mathbf{x}_t)\). This process effectively captures the dynamic progression of the system.
The key property of the Koopman operator \(\mathcal{K}\) is its linearity. This linearity holds irrespective of whether the system’s dynamics are linear or nonlinear. Consequently, the spectral properties of \(\mathcal{K}\) become a powerful tool in analyzing the dynamical system’s behavior.
if \(g \in \mathcal{F}\) is an eigenfunction of \(\mathcal{K}\) with eigenvalue \(\lambda\), then:
One of the most useful features of Koopman operators is the Koopman Mode Decomposition (KMD). The KMD expresses the state \(\mathbf{x}\) or an observable \(g(\mathbf{x})\) as a linear combination of dominant coherent structures. It can be considered a diagonalization of the Koopman operator.
As a result, the KMD is invaluable for tasks such as dimensionality and model reduction. It generalizes the space-time separation of variables typically achieved through the Fourier transformor singular value decomposition (SVD).
Dynamic Mode Decomposition (DMD)#
Dynamic Mode Decomposition (DMD) is a popular data-driven analysis technique used to decompose complex, nonlinear systems into a set of coherent structures (also called DMD modes), that grow, decay, and/or oscillate in time revealing underlying patterns and dynamics through spectral analysis. In other words, the DMD converts a dynamical system into a superposition of modes whose dynamics are governed by eigenvalues.
The simplest and historically first interpretation of DMD is as a linear regression.
We consider a discrete-time dynamical systems represented as:
Given discrete-time snapshots of the system:
We define the snapshot matrices \(\mathbf{X}, \mathbf{Y} \in \mathbb{C}^{d\times M}\) as:
We seek a matrix \(\mathbf{K}_{\text{DMD}}\) such that \(\mathbf{Y} \approx \mathbf{K}_{\text{DMD}} \mathbf{X}\). We can think of this as constructing a linear and approximate dynamical system.
To find a suitable matrix KDMD, we consider the minimization problem:
where \(\left\lVert . \right\rVert_F\) denotes the Frobenius norm[4]. Similar optimization problems will be at the heart of the various DMD-type algorithms we consider in this review. A solution to the problem in (1) is:
where \(^{+}\) denotes the Moore–Penrose pseudoinverse.
In practice, this is computed using the Singular Value Decomposition (SVD) as follows:
The core goal of DMD is to apply linear algebra and spectral techniques to the analysis, prediction, and control of nonlinear dynamical systems. However, DMD often faces several challenges that have been a driving force for the many versions of the DMD algorithm that have appeared.
Generally speaking, the error of DMD and its approximate KMD can be split into three types:
The projection error is due to projecting/truncating the Koopman operator onto a finite-dimensional space of observables. This is linked to the issue of closure and lack of (or lack of knowledge of) non-trivial finite-dimensional Koopman invariant subspaces.
The estimation error is due to estimating the matrices that represent the projected Koopman operator from a finite set of potentially noisy trajectory data.
Numerical errors (e.g., roundoff, stability, further compression, etc.) incurred when processing the finite DMD matrix.
Variants#
DMD Method |
Challenges Overcome |
Key Insight/Development |
|---|---|---|
Forward-Backward DMD |
Sensor noise bias. |
Take geometric mean of forward and backward propagators for the data. |
Total Least-Squares DMD |
Sensor noise bias. |
Replace least-squares problem with total least-squares problem. |
Optimized DMD |
Sensor noise bias. |
Exponential fitting problem, solve using variable projection method. |
Compressed Sensing |
Computational efficiency. |
Unitary invariance of DMD extended to settings of compressed sensing (e.g., RIP, sparsity-promoting regularizers). |
Randomized DMD |
Computational efficiency. |
Sketch data matrix for computations in reduced-dimensional space. |
Multiresolution DMD |
Multiscale dynamics. |
Filtered decomposition across scales. |
DMD with Control |
Separation of unforced dynamics and actuation. |
Generalized regression for globally linear control framework. |
Extended DMD |
Nonlinear observables. |
Arbitrary (nonlinear) dictionaries, recasting of DMD as a Galerkin method. |
Physics-Informed DMD |
Preserving structure of dynamical systems. |
Restrict the least-squares optimization to lie on a matrix manifold. |
DMD with Control (DMDc)#

Fig. 22 Overview of Dynamic Mode Decomposition with Control (DMDc). Adapted from [PBK16].#
One of the most successful applications of the Koopman operator framework lies in control with demonstrated successes in various challenging appli- cations. These include fluid dynamics, robotics, power grids, biology, and chemical processes.
The key point is that Koopman operators represent nonlinear dynamics within a globally linear framework. This approach leads to tractable convex optimization problems and circumvents theoretical and computational limitations associated with nonlinearity. Moreover, it is amenable to data-driven, model-free approaches.
DMDc extends DMD to disambiguate between unforced dynamics and the effect of actuation.
The DMD regression is generalized to:
where \(A \in \mathbb{C}^{d\times d}\) and $B \in \mathbb{C}^{d\times q} are unknown matrices.
Snapshot triplets of the form \(\{\mathbf{x}^{(m)}, \mathbf{y}^{(m)}, \mathbf{u}^{(m)}\}^M_{m=1}\) are collected, where we assume that:
The control portion of the snapshots is arranged into the matrix \(\Upsilon = \begin{pmatrix}u^{(1)} & u^{(2)} & \dots & u^{(M)}\end{pmatrix}\).
The optimization problem in (1) is replaced by
A solution is given as \(\begin{pmatrix}A & B \end{pmatrix} = \mathbf{Y} \Omega^{+}\).
Comparison#

Fig. 23 Overview of various methods that use regression to identify dynamics from data. Taken from [BPK16b].#
Application to Systems#
Cart#
We will use the DMDc and the SINDYc methods to fit a model on the data collected from the Cart environment.
Data#
Show code cell content
cart_env = create_cart_environment(max_steps=500, goal_position=29, max_position=30)
cart_observations = {}
cart_actions = {}
controllers = {
"Step": ConstantController(np.asarray([cart_env.max_action / 2])),
"Schroeder Sweep": SchroederSweepController(
cart_env,
n_time_steps=500,
n_harmonics=5,
frequency=2,
),
"PRBS": PRBSController(np.asarray([cart_env.max_action])),
}
for controller_name, controller in controllers.items():
result = simulate_environment(cart_env, controller=controller)
cart_observations[controller_name] = result.observations
cart_actions[controller_name] = result.actions
error: XDG_RUNTIME_DIR not set in the environment.
We use the data from the PRBS controller as training data and use the one from the Step controller as validation data.
training_controller_name = "PRBS"
testing_controller_name = "Step"
X_train = cart_observations[training_controller_name][:-1].copy()
U_train = cart_actions[training_controller_name].copy()
t_train = np.arange(0, len(X_train)) * cart_env.dt
X_val = cart_observations[testing_controller_name][:-1].copy()
U_val = cart_actions[testing_controller_name].copy()
t_val = np.arange(0, len(X_val)) * cart_env.dt
SINDYc#
For the SINDYc method we use the pysindy package.
Refer to its introduction page for usage information.
We define an optimizer, a feature library and a differentiation method with appropriate hyper-parameters and then fit the model on the training data
optimizer = ps.STLSQ(threshold=0.1, max_iter=100)
feature_library = ps.IdentityLibrary()
differentiation_method = ps.FiniteDifference(order=1)
sindy_model = ps.SINDy(
optimizer=optimizer,
feature_library=feature_library,
differentiation_method=differentiation_method,
)
sindy_model.fit(X_train, u=U_train, t=t_train)
SINDy(differentiation_method=FiniteDifference(order=1),
feature_library=<pysindy.feature_library.identity_library.IdentityLibrary object at 0x7ff73ef01d80>,
feature_names=['x0', 'x1', 'u0'], optimizer=STLSQ(max_iter=100))In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
SINDy(differentiation_method=FiniteDifference(order=1),
feature_library=<pysindy.feature_library.identity_library.IdentityLibrary object at 0x7ff73ef01d80>,
feature_names=['x0', 'x1', 'u0'], optimizer=STLSQ(max_iter=100))STLSQ(max_iter=100)
STLSQ(max_iter=100)
Once that’s done, we can print the fitted model
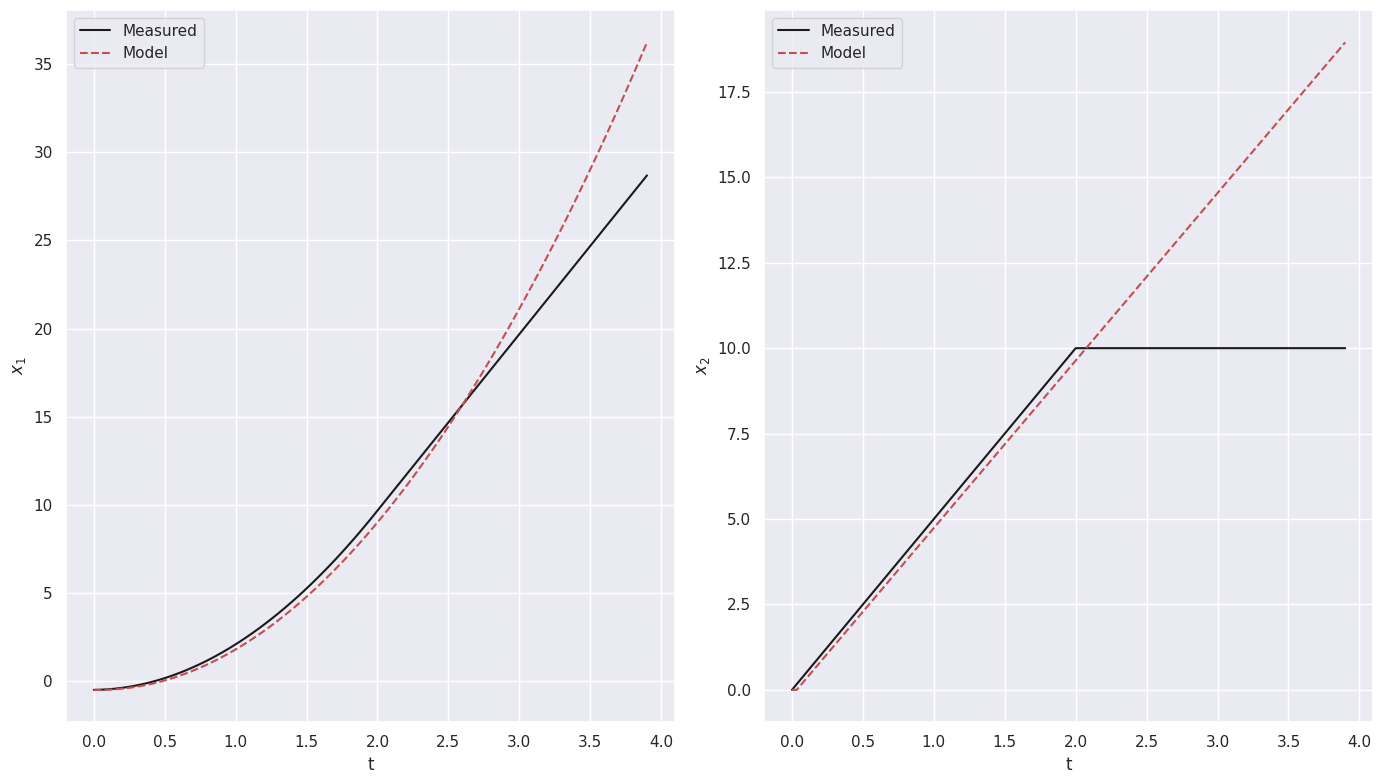
(x0)' = 1.002 x1
(x1)' = 0.980 u0
We can also compute a score for the fitted model.
By default this is computes the \(R^2\) score[5], also called coefficient of determination, but we will instead using the Mean Squared Error metric.
Model score: 5.911230
Let us now use the model to simulate the system’s response with the test inputs and as initial state the first state in the test data
Show code cell content
X_sindy = sindy_model.simulate(X_val[0], t_val, u=U_val)
X_sindy = np.vstack([X_val[0][np.newaxis, :], X_sindy])
DMDc#
For the DMDc method we use the pykoopman package.
Refer to its documentation page for usage information.
We start by defining a regression method, DMDs in this case, with appropriate hyper-parameters.
Afterwards we use that to create and then fit a model on the training data.
DMDc = pk.regression.DMDc(svd_output_rank=4, svd_rank=6)
dmd_model = pk.Koopman(regressor=DMDc)
dmd_model.fit(X_train, u=U_train, dt=cart_env.dt)
Koopman(observables=Identity(), regressor=DMDc(svd_output_rank=4, svd_rank=6))In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Koopman(observables=Identity(), regressor=DMDc(svd_output_rank=4, svd_rank=6))
Identity()
Identity()
DMDc(svd_output_rank=4, svd_rank=6)
DMDc(svd_output_rank=4, svd_rank=6)
Once we fit the model we can access the linear state-space models matrices:
These matrices are different from the ones that we used in our model previously because they are acting on measurements and not on the actual states.
After that we can use the model to simulate the system using the test data.
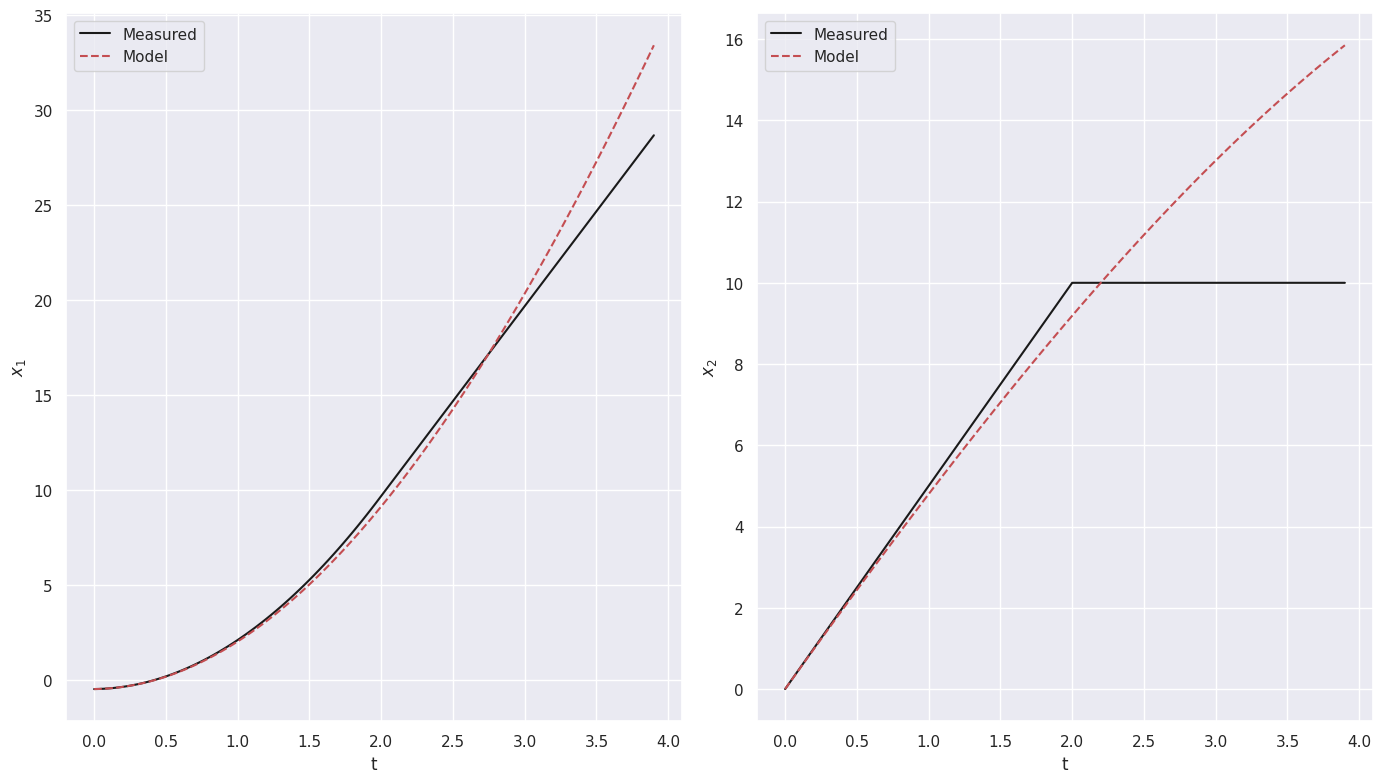
X_dmd = dmd_model.simulate(X_val[0], U_val, n_steps=X_val.shape[0] - 1)
X_dmd = np.vstack([X_val[0][np.newaxis, :], X_dmd])
/opt/conda/lib/python3.10/site-packages/pykoopman/koopman.py:302: ComplexWarning: Casting complex values to real discards the imaginary part
x = x.astype(self.A.dtype)
We can also compute score similarily to what we did for SINDyc
Model score: 3.758127
Inverted Pendulum#
Exercise#
Exercise 7 (Inverted Pendulum)
Use the SINDYc and/or DMDc method to fit a model on the data collected from the inverted pendulum environment.
Solution to ( 7
Show code cell content
inverted_pendulum_env = create_inverted_pendulum_environment(
max_steps=100, theta_threshold=np.inf
)
inverted_pendulum_observations = dict()
inverted_pendulum_actions = dict()
controllers = dict()
for i in range(5):
controllers[f"PRBS {i}"] = PRBSController(
np.asarray([(-1) ** i * inverted_pendulum_env.force_max / (2**i)]), seed=i
)
for controller_name, controller in controllers.items():
result = simulate_environment(inverted_pendulum_env, controller=controller)
inverted_pendulum_observations[controller_name] = result.observations
inverted_pendulum_actions[controller_name] = result.actions
error: XDG_RUNTIME_DIR not set in the environment.
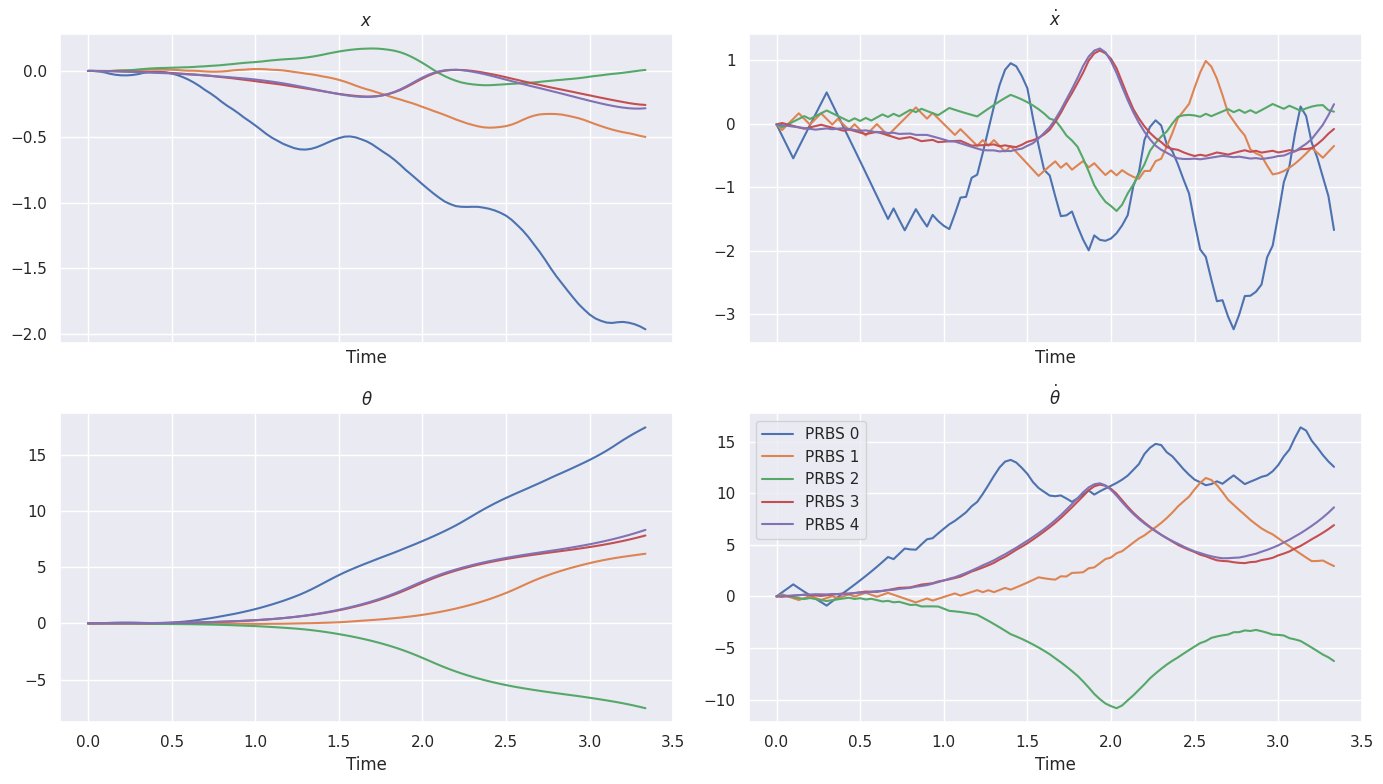
training_controller_name = "PRBS 0"
testing_controller_name = "PRBS 1"
X_train = inverted_pendulum_observations[training_controller_name][:-1].copy()
U_train = inverted_pendulum_actions[training_controller_name].copy()
t_train = np.arange(0, len(X_train)) * inverted_pendulum_env.dt
X_val = inverted_pendulum_observations[testing_controller_name][:-1].copy()
U_val = inverted_pendulum_actions[testing_controller_name].copy()
t_val = np.arange(0, len(X_val)) * inverted_pendulum_env.dt
SINDYc
Show code cell source
optimizer = ps.STLSQ(threshold=0.3, max_iter=500)
feature_library = ps.IdentityLibrary()
differentiation_method = ps.FiniteDifference(order=1)
sindy_model = ps.SINDy(
optimizer=optimizer,
feature_library=feature_library,
differentiation_method=differentiation_method,
)
sindy_model.fit(X_train, u=U_train, t=inverted_pendulum_env.dt)
SINDy(differentiation_method=FiniteDifference(order=1),
feature_library=<pysindy.feature_library.identity_library.IdentityLibrary object at 0x7ff73efa0a30>,
feature_names=['x0', 'x1', 'x2', 'x3', 'u0'],
optimizer=STLSQ(max_iter=500, threshold=0.3))In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
SINDy(differentiation_method=FiniteDifference(order=1),
feature_library=<pysindy.feature_library.identity_library.IdentityLibrary object at 0x7ff73efa0a30>,
feature_names=['x0', 'x1', 'x2', 'x3', 'u0'],
optimizer=STLSQ(max_iter=500, threshold=0.3))STLSQ(max_iter=500, threshold=0.3)
STLSQ(max_iter=500, threshold=0.3)
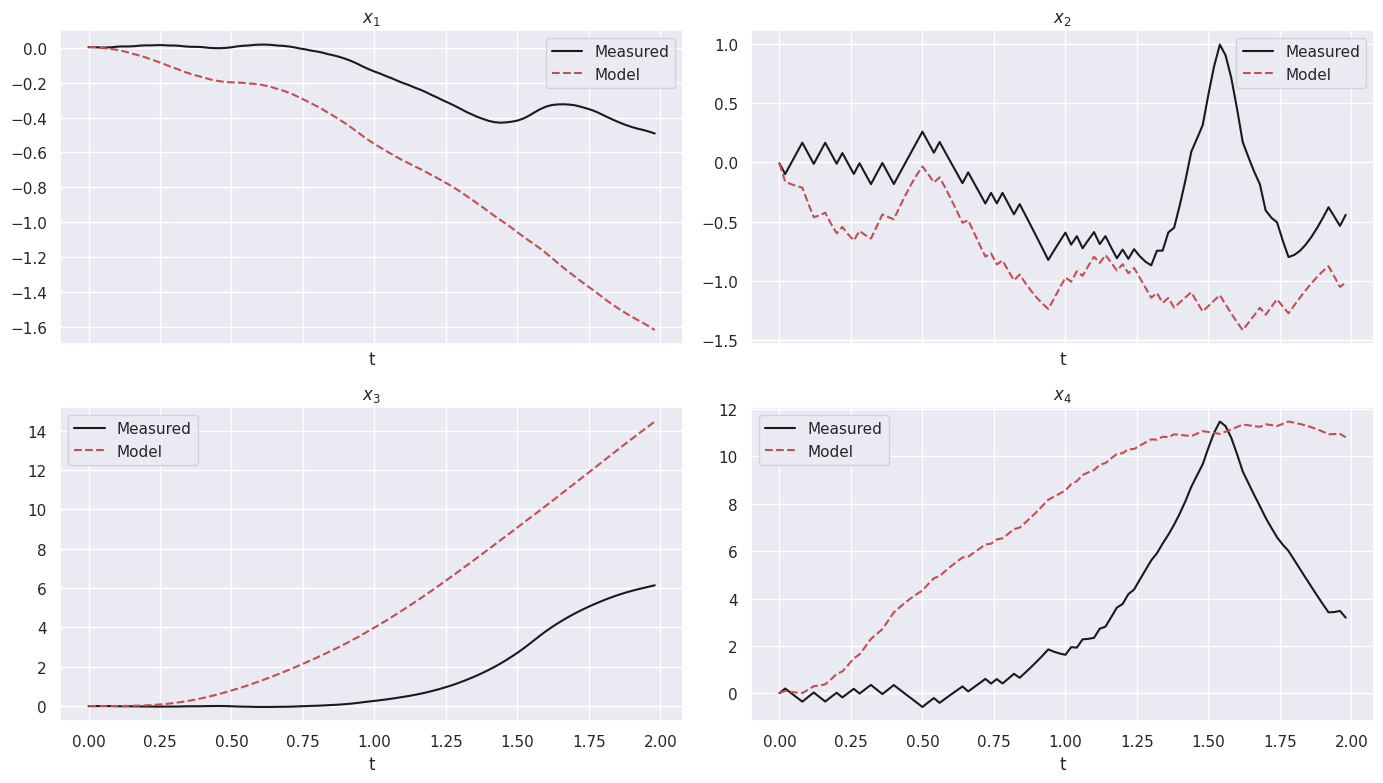
(x0)' = 0.998 x1
(x1)' = -51.462 x0 + -1.826 x1 + -5.233 x2 + -0.885 x3 + 0.651 u0
(x2)' = 1.001 x3
(x3)' = -107.086 x0 + -5.116 x1 + -12.393 x2 + -0.517 x3 + -0.698 u0
Model score: 32.144658
X_sindy = sindy_model.simulate(X_val[0], t_val, u=U_val)
X_sindy = np.vstack([X_val[0][np.newaxis, :], X_sindy])
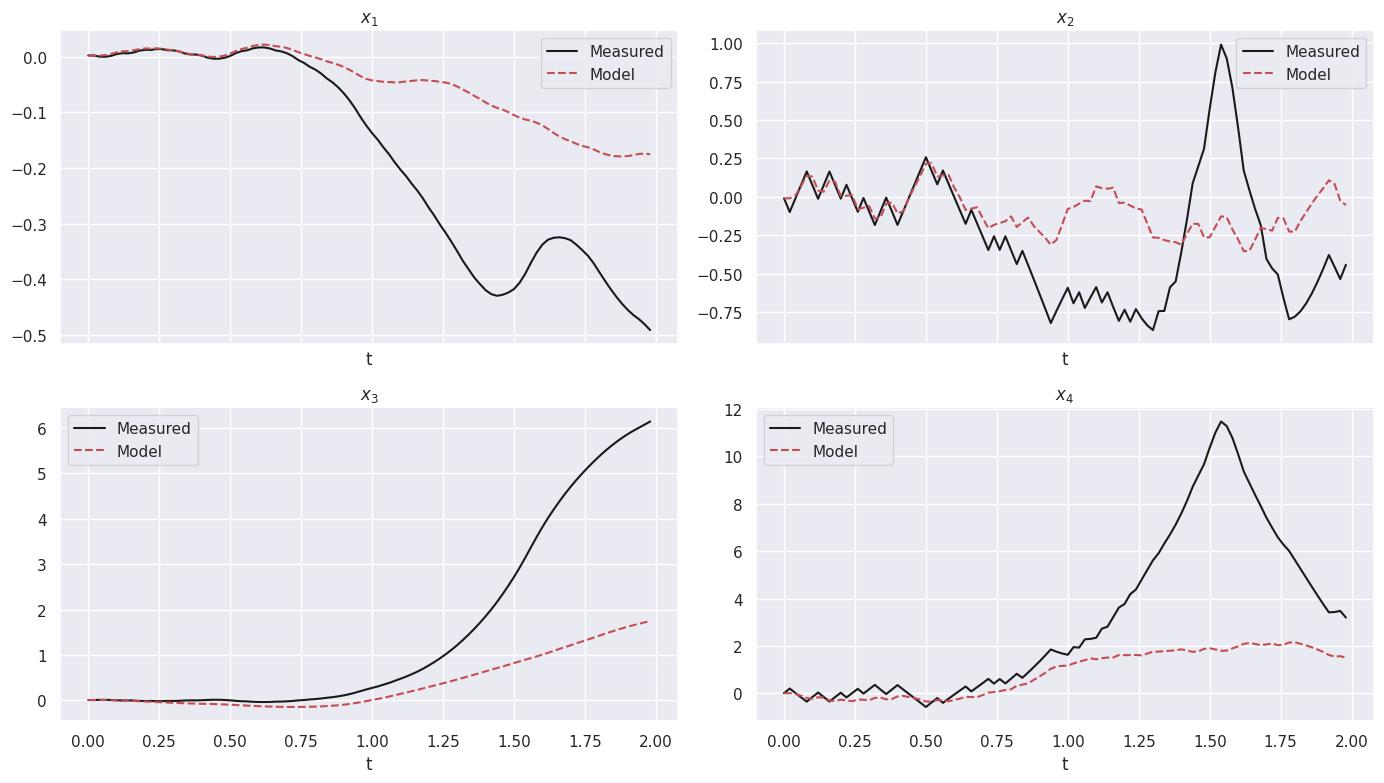
DMDc
Show code cell source
regressor = pk.regression.EDMDc()
observables = pk.observables.Polynomial(degree=1)
dmd_model = pk.Koopman(observables=observables, regressor=regressor)
dmd_model.fit(X_train, u=U_train, dt=inverted_pendulum_env.dt)
/opt/conda/lib/python3.10/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_input_features_` was deprecated in version 1.0 and will be removed in 1.2.
warnings.warn(msg, category=FutureWarning)
/opt/conda/lib/python3.10/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_input_features_` was deprecated in version 1.0 and will be removed in 1.2.
warnings.warn(msg, category=FutureWarning)
/opt/conda/lib/python3.10/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_input_features_` was deprecated in version 1.0 and will be removed in 1.2.
warnings.warn(msg, category=FutureWarning)
/opt/conda/lib/python3.10/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_input_features_` was deprecated in version 1.0 and will be removed in 1.2.
warnings.warn(msg, category=FutureWarning)
Koopman(observables=Polynomial(degree=1), regressor=EDMDc())In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Koopman(observables=Polynomial(degree=1), regressor=EDMDc())
Polynomial(degree=1)
Polynomial(degree=1)
EDMDc()
EDMDc()
X_dmd = dmd_model.simulate(X_val[0], U_val, n_steps=X_val.shape[0] - 1)
X_dmd = np.vstack([X_val[0][np.newaxis, :], X_dmd])
/opt/conda/lib/python3.10/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_input_features_` was deprecated in version 1.0 and will be removed in 1.2.
warnings.warn(msg, category=FutureWarning)
/opt/conda/lib/python3.10/site-packages/pykoopman/koopman.py:302: ComplexWarning: Casting complex values to real discards the imaginary part
x = x.astype(self.A.dtype)
Model score: 11.334027